
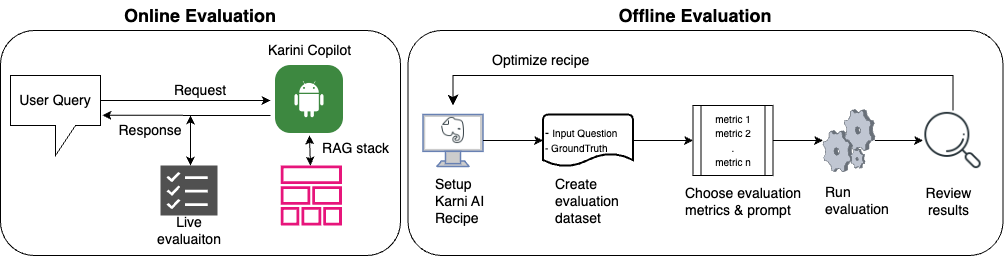
Retrieval-augmented Generation(RAG) has become the industry standard for developing chatbots due to its ability to reduce hallucinations and leverage domain-specific knowledge. However, the process of evaluating its effectiveness remains challenging and complex. A RAG system is a sophisticated combination of multiple components, such as a retrieval module and a generation component represented by large language models (LLMs). These components work together to provide contextually relevant and accurate responses, yet each operates differently and requires distinct evaluation methodologies. The complexity of these systems underscores the need for advanced evaluation techniques. The difficulty lies in assessing the overall end-to-end performance of the RAG system, as traditional evaluation metrics often need to be revised to capture the nuances and dependencies between these components. Additionally, the absence of standardized benchmarks for RAG systems further complicates the evaluation process, making it challenging to compare different approaches and select the most suitable one for specific use cases.
The need for sophisticated RAG evaluation mechanisms is clear. For instance, evaluating the faithfulness of generated content, ensuring the relevance of retrieved context, and balancing factual accuracy with language coherence are all critical aspects that must be rigorously assessed. The importance of these assessments cannot be overstated, as they are key to the successful deployment and operation of RAG systems. Moreover, diagnosing errors within the system, tracing them back to their sources, and ensuring that the system remains robust and reliable across different scenarios is essential for successful deployment. Developing advanced evaluation frameworks to address these challenges is crucial for RAG architectures' broader adoption and success in real-world applications. Like machine learning projects, you can evaluate the performance of an RAG pipeline using a validation dataset and an appropriate evaluation metric. However, while this approach is practical, creating a high-quality validation dataset with human annotators can be challenging, time-intensive, and costly.
Karini AI offers a comprehensive and efficient solution for RAG evaluation. It provides the unique ability to conduct live “reference-free” (online) evaluation of your chatbot and offline evaluation using predefined or custom metrics and an evaluation dataset. By leveraging Karini AI, you can streamline the evaluation process, reduce the need for human annotators, and significantly reduce time and costs. This efficiency instills confidence in the evaluation process, allowing you to focus on the quality and performance of your RAG system. With Karini AI, you can be reassured that your RAG system is being evaluated with the utmost precision and thoroughness.
 .
.
Offline Evaluation
Let's discuss a sample use case by creating a RAG Recipe(application) for the Amazon Shareholder's Assistant Chatbot. A RAG Recipe is a set of instructions that define how the RAG system should operate, including the retrieval and generation components. Once you've crafted your recipe using Karini AI’s intuitive no-code recipe canvas, you can evaluate its effectiveness in delivering high-quality results. For this blog, we have created a RAG (Retrieval-Augmented Generation) recipe that leverages Amazon's annual letters to shareholders as its knowledge base and deploys a chatbot that acts as an Amazon Shareholder assistant chatbot.
The Offline Evaluation Process: The offline evaluation process of your RAG recipe involves creating and uploading an 'evaluation ground-truth' dataset. This dataset serves as a benchmark for evaluating the performance of your RAG system. It consists of a series of questions paired with their corresponding correct answers, all compiled into a .csv file. The evaluation dataset can also be generated using an RAG chatbot using human feedback. You then select specific metrics to assess the responses generated by your RAG (Retrieval-Augmented Generation) recipe during testing. Below is an example of how an evaluation dataset might be structured:
| Question | Ground_Truth Answer |
|---|---|
| How has Amazon's commitment to renewable energy progressed over the years? | In 2020, Amazon was already the world's most significant corporate buyer of renewable energy. By 2023, Amazon continued to expand its renewable energy portfolio, aiming for 100% renewable energy by 2025, five years ahead of its initial 2030 target. |
| How did Amazon's third-party seller profits evolve from 2020 to 2021? | In 2020, Amazon's third-party seller profits were estimated to be between $25 billion and $39 billion. In 2021, these profits grew as Amazon's third-party sales increased, though specific profit figures for 2021 are not provided. |
| How did Amazon’s AWS revenue in 2020 compare to 2021? | In 2020, AWS's revenue was $45 billion. By 2021, AWS continued to grow significantly, contributing a more significant portion to Amazon's overall revenue, though specific figures for 2021 aren't provided. |
| What were Amazon’s total value creation figures for shareholders, employees, third-party sellers, and customers in 2020? | In 2020, Amazon’s value creation was $301 billion, divided into $21 billion for shareholders, $91 billion for employees, $25 billion for third-party sellers, and $164 billion for customers. |
| How did Amazon's response to the COVID-19 pandemic evolve between 2020 and 2021? | In 2020, Amazon focused on employee safety, including increased pay and safety measures. By 2021, Amazon prioritized safety while addressing the pandemic's broader impacts on its supply chain and operations. |
| What was Amazon's revenue growth in 2023? | In 2023, Amazon’s total revenue grew 12% year-over-year from $514B to $575B. By segment, North American revenue increased 12% YoY from $316B to $353B, International revenue grew 11% YoY from $118B to $131B, and AWS revenue increased 13% YoY from $80B to $91B. |
| What were the key components of Amazon’s leadership principles in 2020, and how did they influence the company's operations? | In 2020, Amazon’s leadership principles emphasized customer obsession, ownership, and innovation. These principles guided Amazon's decisions and were integral to its growth and success. |
After creating and uploading your evaluation dataset using the “Evaluation” component in Karini’s recipe, you can choose from the following metrics to carry out the evaluation.
Answer Relevance: is a metric that evaluates how relevant the generated answer is to the question. It measures the degree to which a response directly addresses and is appropriate for a given question. This metric is crucial for assessing the quality of the RAG system's responses.
Faithfulness: Measures the factual accuracy of the generated answer against the retrieved context.
Context Relevance: Measures how relevant the retrieved context is to the question.
Context Recall: This evaluates whether all the relevant information required to answer the question was retrieved. Context recall measures the extent to which the retrieved context aligns with the annotated answer, treated as the ground truth.
Context Precision: Measures the signal-to-noise ratio of the retrieved context. Ensures the context covers the important aspects of the correct answer from the evaluation (ground-truth) dataset.
Context Entity Recall: Measures if the context includes key entities from the correct answer.
Answer Similarity: Evaluates semantic similarity between the generated and reference answers.
Answer Correctness: Checks if the answer is accurate compared to the correct answer. Answer correctness encompasses two critical aspects: semantic similarity between the generated answer and the ground truth and factual similarity.
Here's the RAG recipe for creating the Amazon Shareholder's Assistant chatbot and the offline evaluation process. This chatbot leverages Amazon's annual letters to shareholders as its knowledge base.
The table below presents an example of evaluation results for a question in the dataset. It includes the response generated by the RAG recipe and a detailed breakdown of each metric and corresponding scores, providing a comprehensive view of the evaluation process.
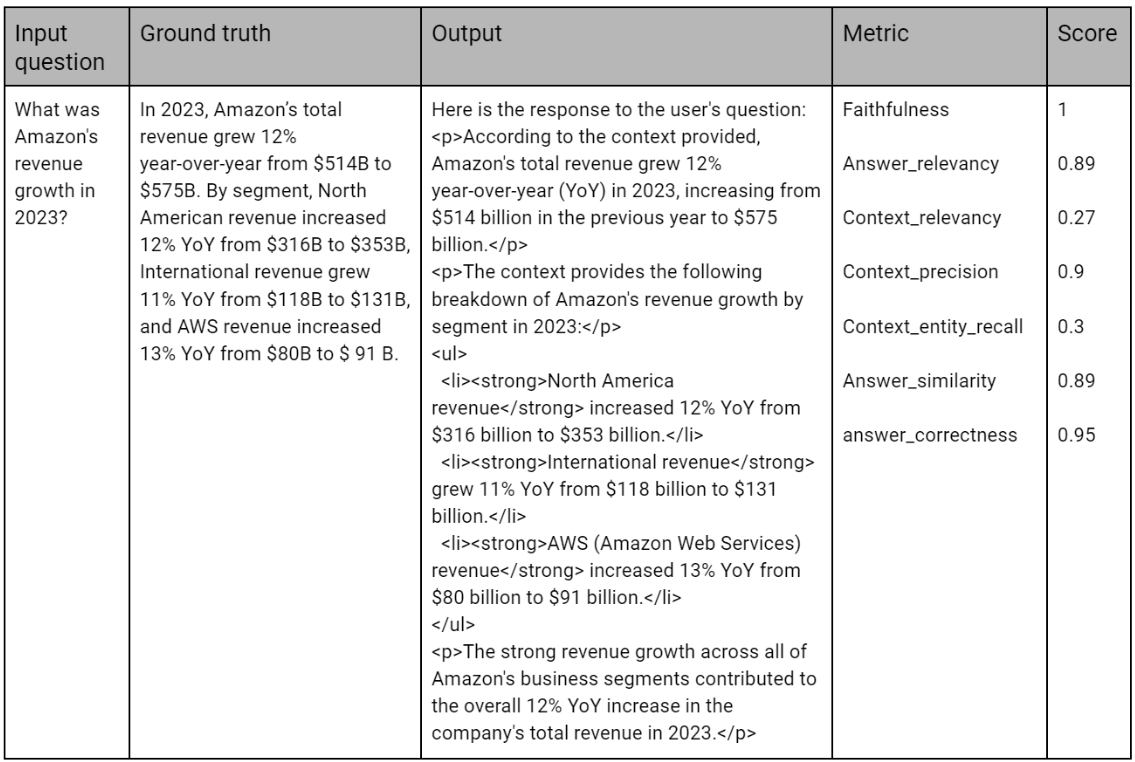
By systematically comparing the generated responses to the ground-truth dataset, you can fine-tune your recipe to enhance accuracy, relevance, and contextual alignment, ensuring that your AI-driven solutions perform optimally in real-world scenarios. Below is an example of how an evaluation dataset might be structured, illustrating the practical steps needed to achieve reliable, high-quality outcomes from your AI deployments.
Custom Evaluation
Organizations often have unique requirements and objectives when building their Retrieval-Augmented Generation (RAG) systems. In such cases, predefined evaluation metrics may only partially capture the nuances of their specific use cases. Recognizing this, Karini AI offers robust capabilities to define and implement custom evaluation metrics tailored to the organization's needs. With Karini's innovative prompt playground, users can start with one of the evaluation prompt templates that include detailed metrics definitions, evaluation guidelines, and scoring criteria. These templates can be customized to conduct evaluations that are more aligned with your goals, ensuring their RAG systems meet the desired quality and performance standards. By allowing the flexibility to configure these custom evaluations, Karini AI supports enterprises in refining and optimizing their RAG applications for a wide range of scenarios.
Here is an example of a multi-metric evaluation prompt crafted using Karini AI’s prompt playground.
Objective:
Determine how correctly and completely the model's Evaluation Output corresponds to the Evaluation Input and, importantly, with the Ground Truth. The evaluation should strictly follow the given metric and grading criteria, giving significant importance to the Ground Truth in terms of relevant, accurate, and comprehensive responses.
Metric Names and Descriptions:
Metric 1:
- Name: Answer Relevance
Description: Answer Relevance determines how directly and relevantly the generated answer addresses the question. A relevant answer is focused and informative, directly tackling the posed question.
Metric 2:
- Name: Factual Accuracy
- Description: Factual Accuracy assesses the correctness of the facts presented in the generated answer. A factually correct answer aligns perfectly with the ground truth.
Metric 3:
- Name: Coherence
- Description: Coherence evaluates the logical flow and readability of the generated answer.
Grading Criteria For Metric 1:
Excellent (5): The answer fully addresses the question, covering all key aspects.
Good (4): The answer addresses the question well, with minor omissions.
Fair (3): The answer partially addresses the question but needs significant details.
Poor (2): The answer is minimally relevant and misses important parts.
Irrelevant (1): The answer does not address the question or is entirely off-topic.
Grading Criteria For Metric 2:
Correct (5): All facts are accurate and align perfectly with the ground truth.
Mostly Correct (4): Minor inaccuracies that don't significantly affect the overall correctness.
Partially Correct (3): There are several inaccuracies, but the answer is somewhat correct.
Mostly Incorrect (2): The answer contains significant factual errors.
Incorrect (1): The answer is factually inaccurate.
Grading Criteria For Metric 3:
Highly Coherent (5): The answer is well-structured, clear, and easy to follow.
Mostly Coherent (4): The answer is clear but may have minor structural issues.
Moderately Coherent (3): The answer has some logical flow but could be clearer to follow.
Poorly Coherent (2): The answer needs clear structure and is hard to follow.
Incoherent (1): The answer is jumbled, confusing, and lacks logical flow.
Evaluation Input:
{Evaluation Input}
Evaluation Ground Truth:
{Evaluation Ground Truth}
Recipe Output:
{Recipe Output}
Output Format (JSON string) example with key-values for each metric:
[{{'metric_name': 'metric-1-name', 'score': x1, 'justification': 'Provide justification for metric 1 here.'}}, {{'metric_name': 'metric-2-name', 'score': x2, 'justification': 'Provide justification for metric 2 here.'}}]
Note: Ensure that each entry in the output array corresponds to one of the metrics listed. The 'score' should reflect the assessment based on the specific grading criteria for that metric, and the 'justification' should concisely capture the rationale behind the assigned score. The number of objects in the output array should match the number of metrics being evaluated.
In this prompt example, we are evaluating the following metrics:
- Answer Relevance
- Factual Accuracy
- Coherence
In Karini AI’s prompt playground, you can test and compare your custom evaluation prompts across various LLMs and model configurations, allowing you to fine-tune and select the optimal model for your RAG application. Leveraging an innovative LLM-as-a-judge approach, Karini AI evaluates your RAG recipes using custom-defined metrics, ensuring the generated responses align closely with the ground-truth dataset. The evaluation model acts as an objective “judge,” providing insights into how well the RAG system performs against your specific criteria, enabling you to refine and optimize your prompts for superior results.
After creating and uploading your evaluation dataset using the “Evaluation” component in Karini’s recipe, you can select the “Custom evaluation” option and associate your evaluation prompt.
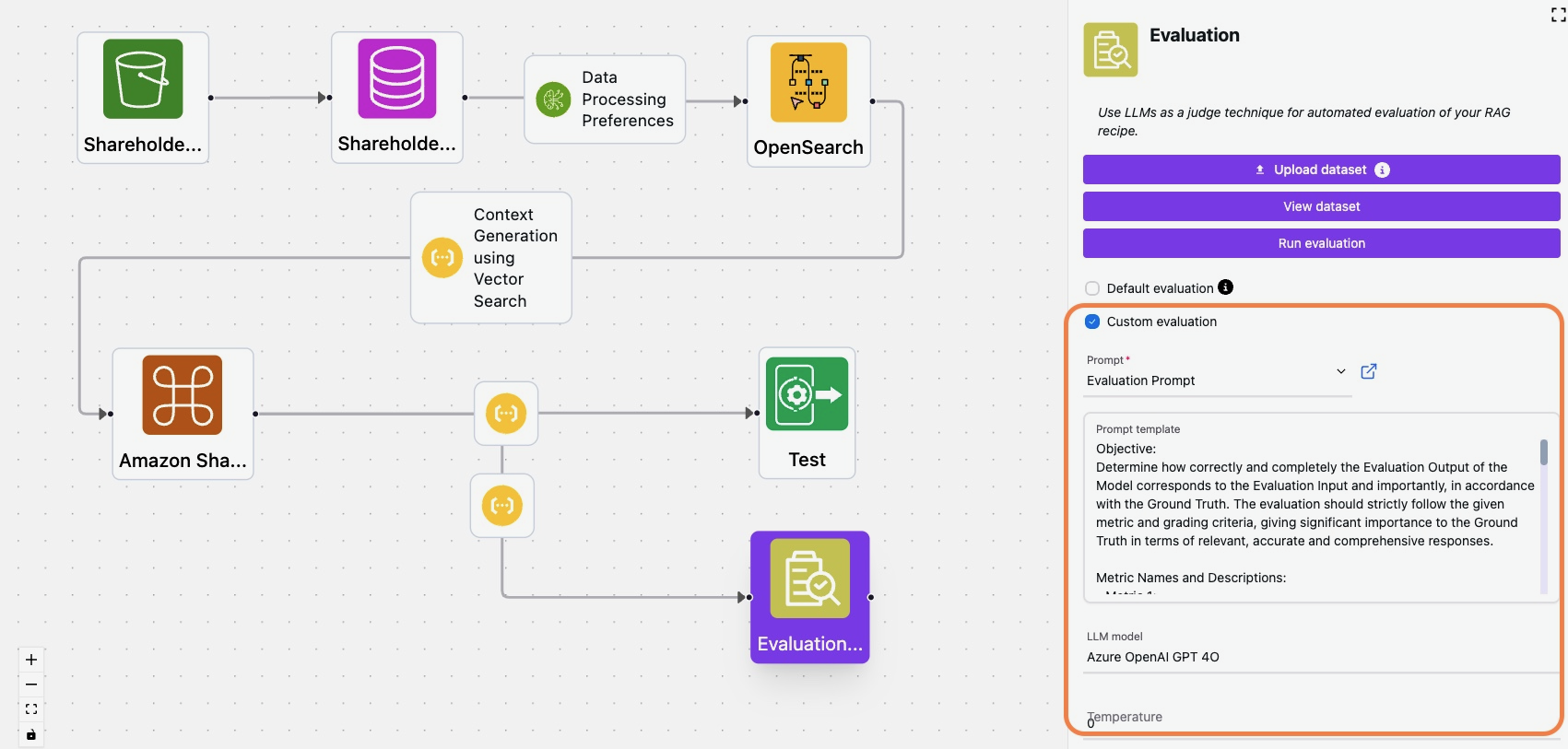
The table below presents the evaluation results for each question in the dataset. It includes the response generated by the RAG recipe, a detailed breakdown of the custom metric scores, and corresponding justifications for each.
| Input question | Ground truth | Output | Metric | Score | Justification |
|---|---|---|---|---|---|
| What were the key components of Amazon’s leadership principles in 2020, and how did they influence the company's operations? | In 2020, Amazon’s leadership principles emphasized customer obsession, ownership, and innovation. These principles guided Amazon's decisions and were integral to its growth and success. | Here is a detailed response to the user's question: According to the context provided, in 2021, Amazon added two new Leadership Principles: "Strive to be Earth's Best Employer" and "Success and Scale Bring Broad Responsibility." These new principles were meant to clarify what was previously implicit at Amazon, empowering more Amazonians to evaluate whether the company is living up to these principles. | Answer Relevance | 2 | It misses key 2020 principles and focuses on 2021 additions. |
| What were the key components of Amazon’s leadership principles in 2020, and how did they influence the company's operations? | In 2020, Amazon’s leadership principles emphasized customer obsession, ownership, and innovation. These principles guided Amazon's decisions and were integral to its growth and success. | Here is a detailed response to the user's question: According to the context provided, in 2021, Amazon added two new Leadership Principles: "Strive to be Earth's Best Employer" and "Success and Scale Bring Broad Responsibility." These new principles were meant to clarify what was previously implicit at Amazon, empowering more Amazonians to evaluate whether the company is living up to these principles. | Factual Accuracy | 3 | It is accurate for 2021 but not aligned with 2020 ground truth. |
| What were the key components of Amazon’s leadership principles in 2020, and how did they influence the company's operations? | In 2020, Amazon’s leadership principles emphasized customer obsession, ownership, and innovation. These principles guided Amazon's decisions and were integral to its growth and success. | Here is a detailed response to the user's question: According to the context provided, in 2021, Amazon added two new Leadership Principles: "Strive to be Earth's Best Employer" and "Success and Scale Bring Broad Responsibility." These new principles were meant to clarify what was previously implicit at Amazon, empowering more Amazonians to evaluate whether the company is living up to these principles. | Coherence | 5 | It is well-structured, straightforward, and easy to follow. |
These examples show that LLM-as-a-Judge has flagged the first metric scores as low and provided appropriate justification for the verdict. This indicates that we should optimize the RAG to improve answer relevance and factual accuracy by fine-tuning the prompt and improving the retrieval process by adjusting Top-N retrieved chunks after reranking.
Online Evaluation
Karini AI offers advanced capabilities to perform a real-time evaluation of your copilot’s or RAG chatbot’s responses without needing a pre-existing evaluation dataset. This innovative approach allows continuous assessment and improvement of the copilot/chatbot’s performance across multiple criteria. The evaluation process includes:
- Faithfulness Assessment: This feature automatically verifies that the responses generated by the chatbot are accurately grounded in the relevant context retrieved from the knowledge base. This ensures that the chatbot’s answers are correct and reliable, significantly enhancing the credibility of the responses.
- Answer Relevance: This criterion evaluates the degree to which the chatbot’s answers address the user’s specific queries. By ensuring that each response is directly relevant to the question posed, Karini AI improves the overall effectiveness and user satisfaction with the copilot’s outputs.
- Context Relevance: This metric measures how well the retrieved context aligns with the query, ensuring the information provided is precise and contextually appropriate. This focus on context relevance leads to more accurate and helpful responses, particularly in complex queries where the specificity of information is crucial.
You can choose the online evaluation option and the desired evaluation metrics during the recipe creation. Once the recipe is deployed as a copilot(chatbot), these evaluation metrics will automatically apply to all copilot requests. Each user request processed by the copilot is dynamically evaluated against these metrics, with the evaluation scores being continuously updated in the copilot’s history. This ongoing feedback loop captures the copilot’s performance over time. It provides users with insights into the quality of the responses, empowering them to make informed decisions about fine-tuning the copilot recipe based on outputs.
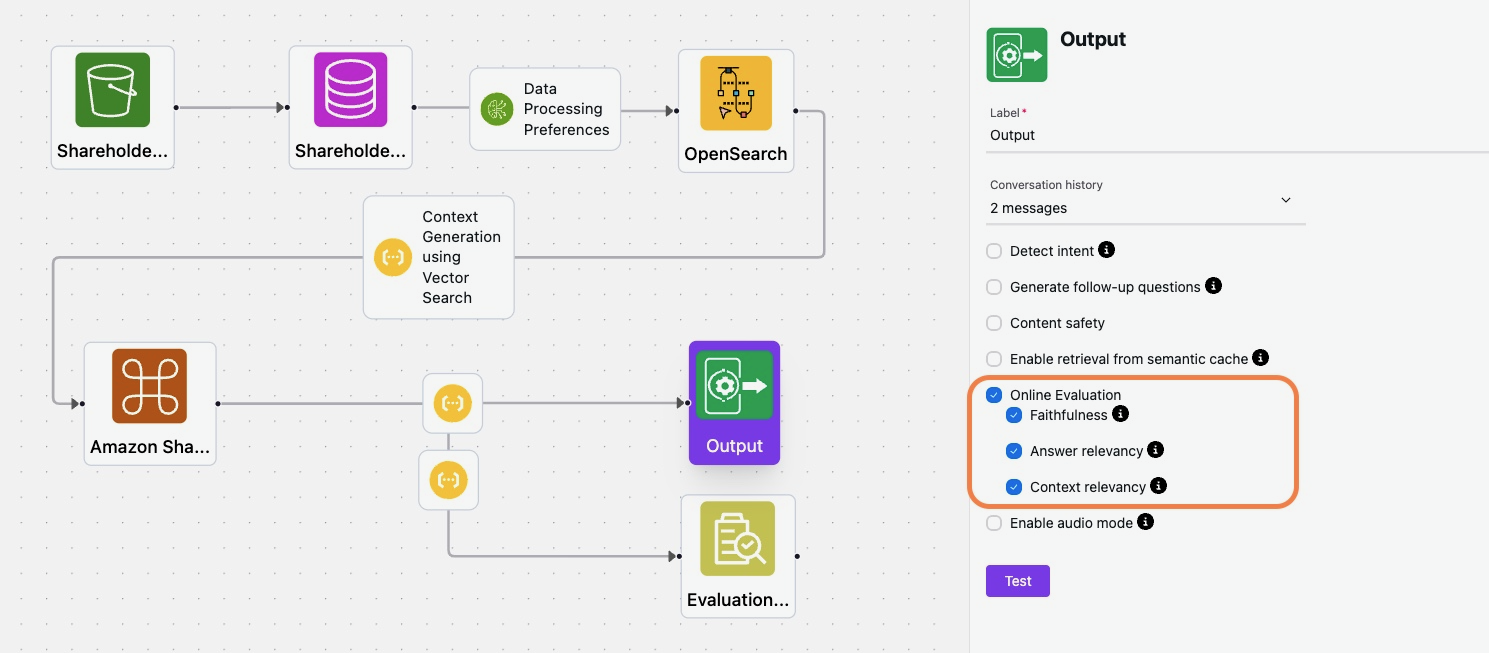
The table below displays user queries, the LLM responses from the Karini AI Copilot, and the corresponding evaluation metrics calculated for each response.
| Question | Generated Answer | Faithfulness Assessment | Answer Relevance | Context Relevance |
|---|---|---|---|---|
| What was Amazon's revenue growth in 2023? | Amazon's Revenue Growth in 2023 In 2023, Amazon experienced significant revenue growth across its various segments. Here are the key details: This growth reflects Amazon's strong performance and continued expansion in various markets. | 0.91 | 0.94 | 0.55 |
| How did Amazon's response to the COVID-19 pandemic evolve between 2020 and 2021? | Here is a detailed response to the user's question about how Amazon's reaction to the COVID-19 pandemic evolved between 2020 and 2021: Amazon's response to the COVID-19 pandemic evolved significantly between 2020 and 2021 as the company navigated the changing business landscape and customer demands: 2020: Rapid Expansion to Meet Surging Demand - In the early part of the 2020 pandemic, Amazon's consumer business grew extraordinarily, with annual revenue increasing from $245 billion in 2019 to $434 billion in 2022. - To keep up with this surge in demand, Amazon had to double its fulfillment center footprint over the prior 25 years and substantially accelerate building a last-mile transportation network. - This rapid expansion was no easy feat, and hundreds of thousands of Amazon employees worked hard to make it happen. 2021: Optimizing Operations and Addressing Challenges - In 2021, Amazon shifted its focus to optimizing its fulfillment and transportation processes to improve productivity and reduce costs. - The company scrutinized every process in its fulfillment centers and transportation network and redesigned scores of processes and mechanisms, resulting in steady productivity gains and cost reductions over the last few quarters. - However, Amazon also faced short-term logistics and cost challenges due to the pandemic, including: - The tightening labor market makes it difficult to receive inventory and place it close to customers - Scarcity and increased costs of ocean, air, and trucking capacity - Disruptions to supply chains and the impact of the Omicron variant and the Russia-Ukraine war on fuel costs and inflation. In summary, Amazon's response to the COVID-19 pandemic evolved from a rapid expansion phase in 2020 to a focus on optimizing operations and addressing various challenges in 2021. The company worked to improve productivity and reduce costs while navigating ongoing supply chain and logistical issues stemming from the pandemic. | 0.8 | 1 | 0.47 |
These examples show that the answer relevance is high, whereas the context relevance is very low. This indicates that while the generated answer is correct or appropriate, the retrieved context may not be closely related to the input query. To improve context relevance, the following strategies can be applied in the Karini AI platform:
- Refine the Retrieval Mechanism: Karini AI’s recipe supports advanced query reconstruction mechanisms. These strategies ensure that the query used to retrieve documents from the knowledge base is precise, considers the nuances of the question, and captures the essential context needed to answer the question.
- Rank context by relevance: Karini AI supports context reranking, which prioritizes the most relevant chunks of context. This helps ensure that the context used to generate responses is highly relevant and accurate.
- Improve embedding techniques: Karini AI’s recipe enables you to refine your chunking and embedding process by tweaking the chunk size, chunk overlap, and chunking strategies, such as semantic chunking and recursive chunking. You can also try different embedding models to improve the ability to capture and represent context, which can lead to more accurate retrieval of contextually relevant information.
In the second example, faithfulness can be improved by applying the following strategies when crafting your prompts in Karini AI:
- Strengthen Context-Response Alignment: Ensure that the generated response is tightly aligned with the context retrieved. Karini AI’s prompt playground enables you to extensively test your prompts using various LLMs and parameters and provides necessary statistics to assist you in selecting the best combination.
- Limit Hallucination by Constraining Generation: Constrain LLM’s output to rely more heavily on the retrieved context, reducing the likelihood of the model generating information not grounded in the retrieved data. Such high-quality prompts can be crafted using Karini AI’s innovative prompt playground.
- Incorporate Post-Processing Checks: Enhance your prompts by applying post-processing techniques to cross-check the generated content with the retrieved context. This helps ensure that the generated content is faithful to the source material.
Conclusion
Enterprise can leverage Karini's robust online and offline evaluation capabilities to assess RAG systems, ensuring that generated responses are contextually accurate and meet defined evaluation criteria. This approach helps identify areas for improvement, guaranteeing that the system consistently delivers high-quality results. With comprehensive metrics and scoring, Karini's RAG evaluation facilitates informed decision-making when deploying and scaling RAG systems across various applications. It also empowers you to determine whether RAG is sufficient for your use case. You can opt for fine-tuning or continued pre-training to develop custom models tailored to your domain, organization, and use case. By utilizing automated evaluation frameworks, Karini minimizes the reliance on manual grading, saving time and resources while maintaining high-quality outcomes.


