
Introduction to GenAIOps in Enterprises
Enterprises are adopting Generative AI to help solve many complex use cases with natural language instructions. Building a Gen AI application involves multiple components such as an LLM, data sources, vector store, prompt engineering, and RAG. GenAIOps defines operational best practices for the holistic management of DataOps (Data Operations), LLMOps (Large Language Model Life cycle management), and DevOps (Development and Operations) for building, testing, and deploying generative AI applications.
Challenges in GenAIOps Automation
While pilot projects using Generative AI can start effortlessly, most enterprises need help progressing beyond this phase. According to Everest Research, a staggering 50%+ projects do not move beyond the pilots as they face hurdles due to the absence of established GenAIOps practices. Each step presents unique challenges, from connecting to enterprise data to navigating the complexities of embedding algorithms and managing query phases. These include:
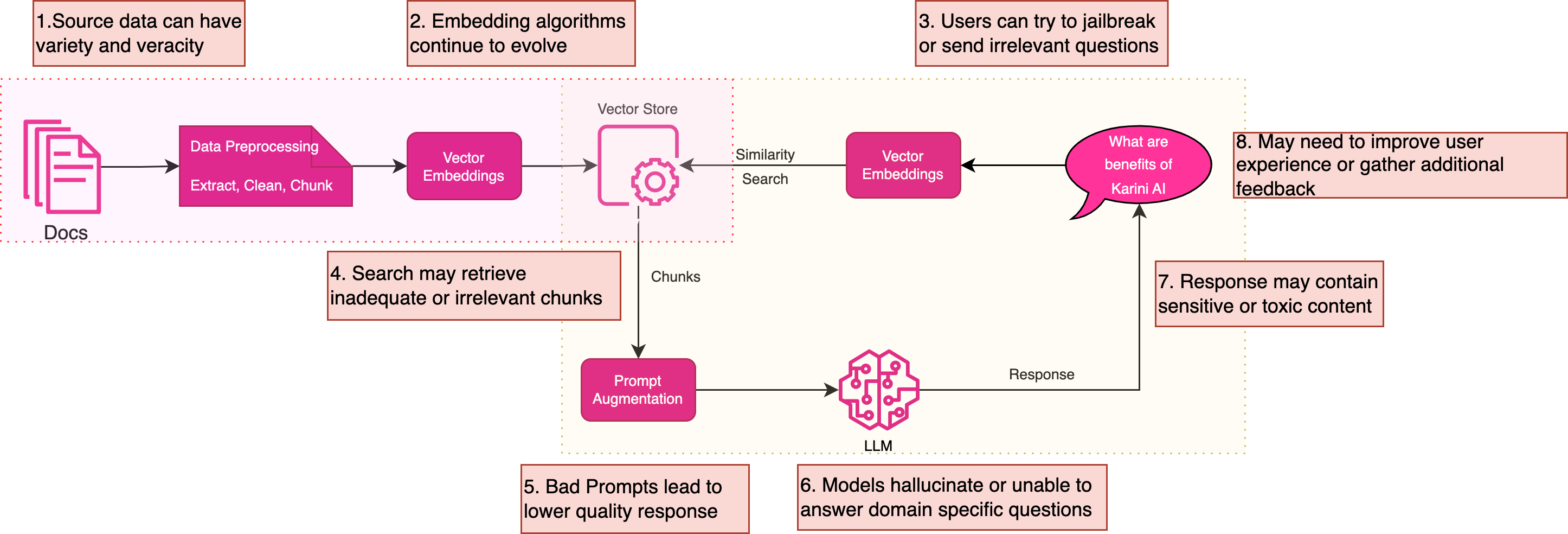
Access to Enterprise Data: This involves creating connectors to various storage solutions and databases, considering different ingestion formats like files, tabular data, or API responses. Unlike traditional ETL, extraction, cleaning, masking, and chunking techniques require special attention, especially when dealing with complex structures like tables in PDFs or removing unwanted HTML tags from web crawls.
Embedding Algorithms: The constantly evolving nature of embedding algorithmsRefer MTEB Leaderboard means it's crucial to experiment with the top models to select the most effective one for your needs. Failure to do so can adversely impact the search process.
Query Phase Management: This phase can be vulnerable to adversarial actors who may try to 'jailbreak' (refer to jailbreakchat) the prompts or overwhelm the system, impacting other users and potentially causing a cost spike.
Chunk Retrieval Process: For the chunk retrieval process, the similarity search may not retrieve adequate information or be unable to retrieve matching chunks, leading to insufficient context for comprehensive and relevant answers. Advanced retrieval chains are required to augment prompts with personalized context. (e.g., What are claims exclusions for “my” insurance plan? ) Prompt Efficiency: Open source LLMs are catching up fast with proprietary LLMs in language understanding, as evident in the open LLMs leaderboard. Hence, writing efficient prompts is very important to get a relevant and comprehensive answer. Bad prompts can either confuse the LLMs or lead to inadequate responses.
Prompt Efficiency: Open source LLMs are catching up fast with proprietary LLMs in language understanding, as evident in the open LLMs leaderboard. Hence, writing efficient prompts is very important to get a relevant and comprehensive answer. Bad prompts can either confuse the LLMs or lead to inadequate responses.
Understanding the Enterprise Domain: While Generative AI effectively addresses numerous inquisitive challenges within enterprises, Large Language Models (LLMs) often struggle to grasp the specific nuances of individual enterprise domains. LLMs are trained on publicly available datasets by crawling the world wide web, but enterprise data is behind firewalls; hence, LLMs may not understand a specific internal term used within a business, leading to an “I don't know” response or a response related to a similar term in Wikipedia dictionary leading to hallucination.
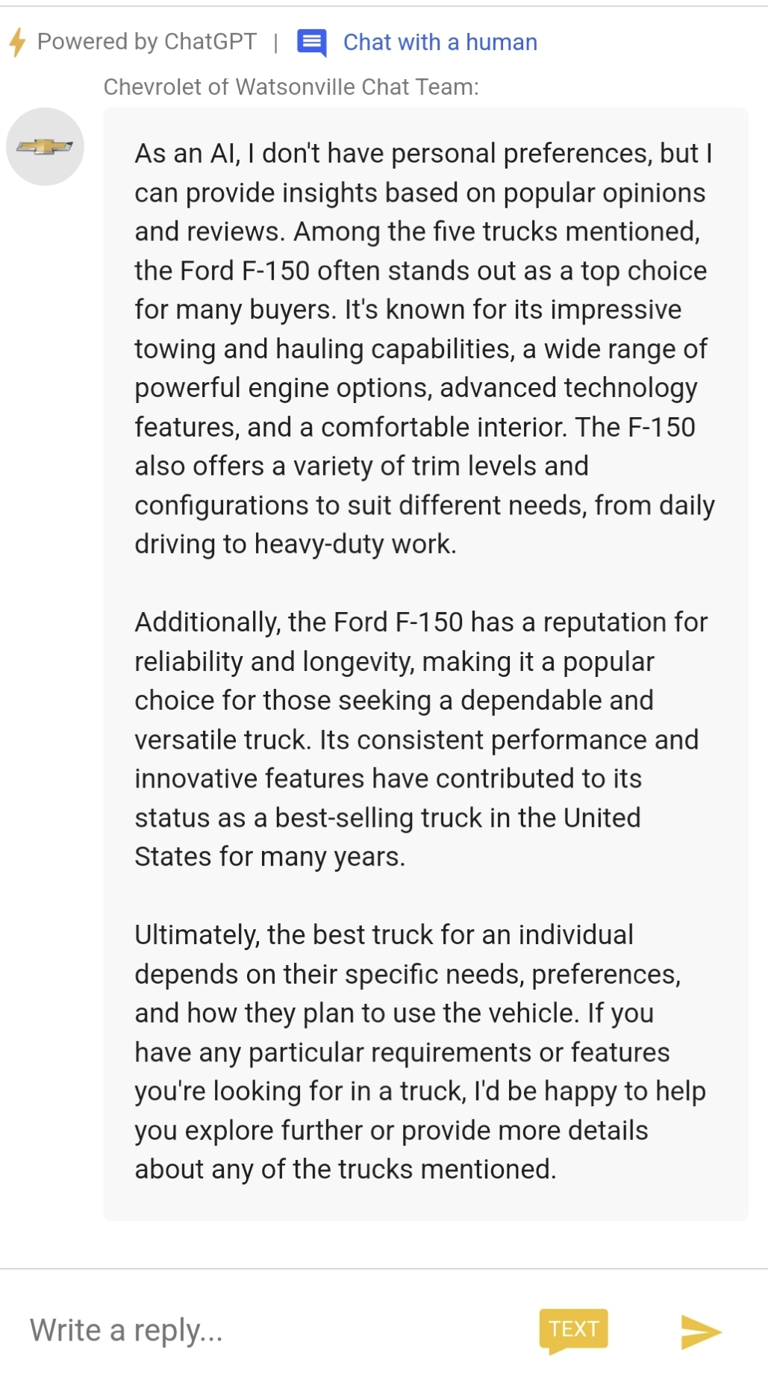
Content Safety: LLMs may spout toxic or unsafe content without proper guardrails, leading to brand reputation issues. The brand reputation concern is genuine, as reported by Chevrolet’s public AI chatbot(MSN), which produced results touting Ford's products. Imagine building these AI chatbots for children or other uninformed or vulnerable populations that may be led astray with misinformation.
User Experience: Most Gen AI systems do not focus on end-user experience. Chat GPT has set the standard for user experience, but OpenAI has control of the end-to-end pipeline, including the model. Lack of good experiences, such as streaming responses, A/B testing framework, lack of exhaustive user feedback mechanism, adequate seeding questions, or lack of follow-up questions, may diminish user engagement.
Getting started with GenAIOps automation is another hurdle due to its technical complexity, specialized skills, and the evolving nature of the field. Organizations must prepare for a learning curve and potentially invest in training to tackle these challenges effectively. A typical enterprise may require 15+ specialized applications to encompass different departments and external applications. Let's dive deep into GenAIOps' best practices to tackle these challenges.
GenAIOps Best practices for enterprises
Effective GenAIOps operationalization requires skills such as AI engineers, safety and security experts, and domain experts. The diagram below provides best practices for a typical RAG workflow depicted in the challenges section. Let's dive into the best practices below,
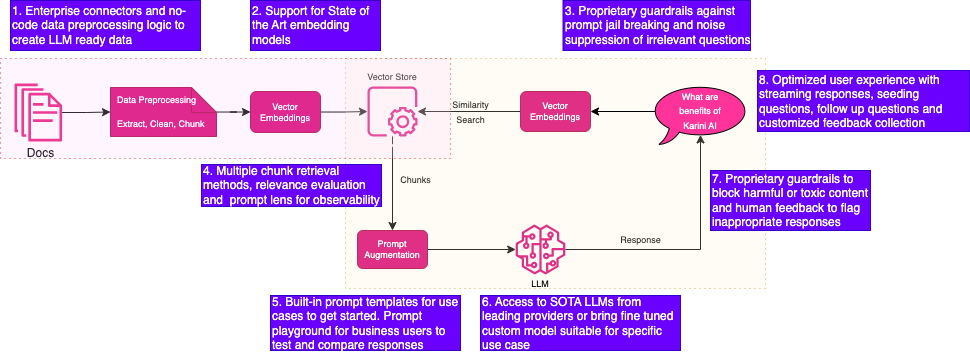
Data Management: Utilize standard storage, database, and SaaS application interfaces to minimize bulk distributed data replication and incremental ingestion. To make it LLM-ready, utilize distributed runtimes for extraction, cleaning, masking, and chunking data. Maintain a copy of source metadata to the vector store to ensure downstream querying systems can use it for pre-filtering for more relevant answers.
Model Selection: Depending on your dataset, use the most appropriate embedding model for your use case. Try at least the top 2 embedding model techniques (Refer MTEB Leaderboard) during the experimentation phase to understand search relevance based on human-generated standard questions and answer pairs. Utilize synthetic questions generated by LLMs if you don't have human-generated question-answer pairs.
Query Management: To prevent intentional or unintentional adverse behavior, use a suitable classification model to block questions and provide canned responses. Monitor adverse prompts for trends and take appropriate action to improve classification methods iteratively. To safeguard against spam attacks, enable user- and token-based throttling to limit attack vectors.
Retrieval Optimization: Use user metadata for pre-filtering to produce a narrower set for semantic search for optimal retrieval. Many vector databases, such as OpenSearch, MongoDB, and Pinecone, provide hybrid search capabilities. Depending on your source datasets, use additional retrieval chains to retrieve the entire or partial document to provide adequate context for your LLM query. For example, in an R&D chatbot, if the user asks to summarize a particular science paper, your retrieval chain must retrieve the entire science paper based on matching chunks.
Building Efficient System Prompts: Building system prompts is the most critical task to get the most optimal response. Due to the lack of a universal framework for prompts, ensure you follow the standards most appropriate based on LLM or your task (e.g., conversation, summarization, or classification). Maintain a library of best practice prompts for enterprise-specific use cases to benefit others. Including and enabling domain experts to design system prompts is essential as they are intimately familiar with datasets and expected outputs. Provide a prompt playground so domain experts can intuitively write system prompts, including examples, “Do not” rules, and expected response format. Provide a playground to quickly compare against authorized models for your enterprise. Maintain versions of the prompts so you can promote the best version to production.
Model Experimentation: Many enterprises start with SaaS model providers such as Azure OpenAI or Amazon Bedrock. Open-source models such as Llama2, Mistral, and MPT and their variants are catching up fast. Try out your application against at least 2-3 leading SOTA models to understand response time, domain understanding, and quality of response. Typical enterprise applications may not need the bells and whistles of multi-headed SaaS models, so using open-source models may be as effective as you scale out and offer a better price per performance. For the rapid testing, build an evaluation script to utilize the”LLM as a judge” approach to compare the responses' relevance, comprehensiveness, and accuracy. If the general purpose model does not provide relevant and comprehensive responses, resort to domain-specific fine-tuning or instruction fine-tuning techniques and employ the fine-tuned model in your RAG.
Content Safety: To prevent harmful, toxic responses, augment system prompts to instruct LLMs to redact harmful content from the response. Employ additional controls using other classifiers to block harmful responses entirely to ensure trust and safety. Use a standard set of questions for automated testing to ensure RAGs are regression tested to account for any changes in LLM, system prompts, or changes in data.
Enhancing User Experience: Ultimately, user experience is essential to increase engagement and attract new users. Add streaming if you are building a conversational system, provide appropriate feedback options so users can rate responses, and volunteer to provide correct responses to build the knowledge base. Provide custom instructions, seeding questions to start the conversation, and follow-up questions. Generative AI is rapidly evolving, so it is vital to continue to monitor user feedback and incorporate additional capabilities such as multi-modal (image and text)
Experts in AI engineering, cloud computing, security, data engineering, and UX engineering built Karini’s Generative AI platform. The combined expertise and platform design provide built-in GenAIOps best practices. These best practices enable enterprises to execute rapid prototyping, production deployment, and continuous monitoring. The Generative AI application's observability capabilities, evaluation, and central performance monitoring allow continuous quality and enterprise governance improvement.
Conclusion
Staying at the forefront of scientific advancement and the evolving landscape of models, Karini AI eliminates technical debt. Our no-code approach to Generative AI application deployment ensures you don’t compromise on quality or speed in bringing products to market. Karini AI is adaptable and perfect for various applications, including virtual assistants, text generation, summarization, Q&A, semantic search, classification, and image creation.


